reading-notes
Automation
shutil — High-level File Operations
The shutil module includes high-level file operations such as copying and archiving.
Copying Files
Python code for copying files using shutil
import io
import os
import shutil
import sys
class VerboseStringIO(io.StringIO):
def read(self, n=-1):
next = io.StringIO.read(self, n)
print('read({}) got {} bytes'.format(n, len(next)))
return next
lorem_ipsum = '''Lorem ipsum dolor sit amet, consectetuer
adipiscing elit. Vestibulum aliquam mollis dolor. Donec
vulputate nunc ut diam. Ut rutrum mi vel sem. Vestibulum
ante ipsum.'''
print('Default:')
input = VerboseStringIO(lorem_ipsum)
output = io.StringIO()
shutil.copyfileobj(input, output)
print()
print('All at once:')
input = VerboseStringIO(lorem_ipsum)
output = io.StringIO()
shutil.copyfileobj(input, output, -1)
print()
print('Blocks of 256:')
input = VerboseStringIO(lorem_ipsum)
output = io.StringIO()
shutil.copyfileobj(input, output, 256)
- The copy() function interprets the output name like the Unix command line tool cp. If the named destination refers to a directory instead of a file, a new file is created in the directory using the base name of the source.
- The permissions of the file are copied along with the contents.
Copying File Metadata
import os
import shutil
import subprocess
with open('file_to_change.txt', 'wt') as f:
f.write('content') `os.chmod('file_to_change.txt', 0o444)`
print('BEFORE:', oct(os.stat('file_to_change.txt').st_mode))
shutil.copymode('shutil_copymode.py', 'file_to_change.txt')
print('AFTER :', oct(os.stat('file_to_change.txt').st_mode))
This example script creates a file to be modified, then uses copymode() to duplicate the permissions of the script to the example file.
Working With Directory Trees
shutil includes three functions for working with directory trees. To copy a directory from one place to another, use copytree().
import glob
import pprint
import shutil
print('BEFORE:')
pprint.pprint(glob.glob('/tmp/example/*'))
shutil.copytree('../shutil', '/tmp/example')
print('\nAFTER:')
pprint.pprint(glob.glob('/tmp/example/*'))
- copytree() accepts two callable arguments to control its behavior.
- The ignore argument is called with the name of each directory or subdirectory being copied along with a list of the contents of the directory.
- It should return a list of items that should be copied. The copy_function argument is called to actually copy the file.
Finding Files
The which() function scans a search path looking for a named file.
import shutil
print(shutil.which('virtualenv'))
print(shutil.which('tox'))
print(shutil.which('no-such-program'))
Archives
Python’s standard library includes many modules for managing archive files such as tarfile and zipfile. There are also several higher-level functions for creating and extracting archives in shutil.
import logging
import shutil
import sys
import tarfile
logging.basicConfig(
format='%(message)s',
stream=sys.stdout,
level=logging.DEBUG, `)`
logger = logging.getLogger('pymotw')
print('Creating archive:')
shutil.make_archive(
'example', 'gztar',
root_dir='..',
base_dir='shutil',
logger=logger, `)`
print('\nArchive contents:')
with tarfile.open('example.tar.gz', 'r') as t:
for n in t.getnames():
print(n)
-
This example starts within the source directory for the examples for shutil and moves up one level in the file system, then adds the shutil directory to a tar archive compressed with gzip.
-
The logging module is configured to show messages from make_archive() about what it is doing.
File System Space
-
It can be useful to examine the local file system to see how much space is available before performing a long running operation that may exhaust that space.
-
disk_usage() returns a tuple with the total space, the amount currently being used, and the amount remaining free.
Python Regular Expression Tutorial
Regular Expressions are a sequence of characters used to check whether a pattern exists in a given text (string) or not.
In Python, regular expressions are supported by the re module. So if you want to use it, you have to import the module first:
import re
Basic Patterns: Ordinary Characters
Ordinary characters can be used to perform simple exact matches:
pattern = r"Cookie"
sequence = "Cookie"
if re.match(pattern, sequence):
print("Match!") `else: print("Not a match!")`
the output will be Match! .
Wild Card Characters: Special Characters
Special characters are characters that do not match themselves as seen but have a special meaning when used in a regular expression.
- A period. Matches any single character except the newline character.
re.search(r'Co.k.e', 'Cookie').group()
- A caret. Matches the start of the string.
re.search(r'^Eat', "Eat cake!").group()
- ’$’ Matches the end of string.
re.search(r'cake$', "Cake! Let's eat cake").group()
-
(“ \ “) Backslash.
- If the character following the backslash is a recognized escape character, then the special meaning of the term is taken (Scenario 1)
- Else if the character following the \ is not a recognized escape character, then the \ is treated like any other character and passed through (Scenario 2).
- \ can be used in front of all the metacharacters to remove their special meaning
Repetitions
- (+) Checks if the preceding character appears one or more times starting from that position.
re.search(r'Co+kie', 'Cooookie').group()
- (*) Checks if the preceding character appears zero or more times starting from that position.
re.search(r'Ca*o*kie', 'Cookie').group()
- (?) Checks if the preceding character appears exactly zero or one time starting from that position.
re.search(r'Colou?r', 'Color').group()
### Summary Table
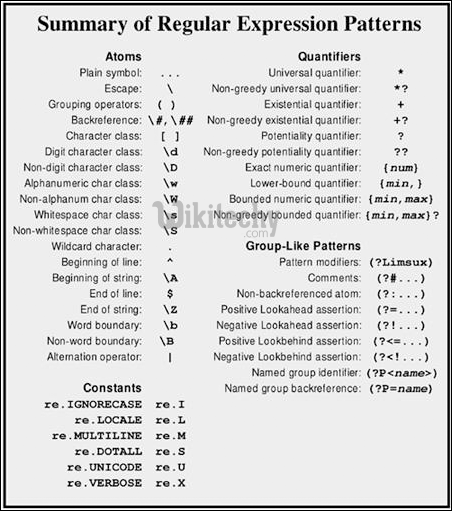
Function provided by ‘re’
The re library in Python provides several functions to make your tasks easier.
Regular expressions are handled as strings by Python. However, with compile(), you can computer a regular expression pattern into a regular expression object.
pattern = re.compile(r"cookie")
sequence = "Cake and cookie"
pattern.search(sequence).group()
Output: ‘cookie’
This is equivalent to:
re.search(pattern, sequence).group()